Your own Bluesky feed
In this post we’ll learn how to build and deploy your own feed on Bluesky. We’ll start with some background info on Bluesky and how feeds work. Then we’ll code and deploy our own feed. Don’t worry about the complexity, it’s mostly filling the gaps in the template.
What’s Bluesky
Bluesky is a decentralized social network. From the end user perspective, it’s very similar to 𝕏 (formerly Twitter). It’s built with AT Protocol which allows programmers to interact with the platform.
Why bother making own feed
What many consider a pain point of social media today is that mysterious algorithms decide what content users will see. Users often have little to no influence over their feeds. Bluesky allows you to create your own algorithm that produces the feed. It’s a very welcome change to get the control back.
Why bother doing it yourself? I see plenty of reasons like:
- Learning opportunity - understanding how decentralized systems work
- Building community - maybe you’re a part of community and want to surface the content you care about to your network
- Tailoring the content for yourself - since you can own the algorithm, there’s nothing preventing you from building a feed tailored to your specific needs
Not only feeds
In this post we’ll build our own feed, but there’s nothing stopping you from integrating with Bluesky in other ways. The opportunities are endless, from feeds through bots, news summaries, building your own relays and a lot more. Platform developers recently published a Call for developer projects from which you can draw some inspiration.
What is a feed anyway?
A feed is a tab in the Bluesky app where you see posts that have been selected by the algorithm. Take this Scala feed as an example.
Behind the scenes, there’s a program whose source code can be found here: https://github.com/polyvariant/scala-feed. The program is running on the feed owner’s server. Whenever Bluesky user wants to see the feed content, the feed program will be asked to produce the results.
Technical explanation
The sequence diagram below explains the role of the feed server in displaying the feed upon user request
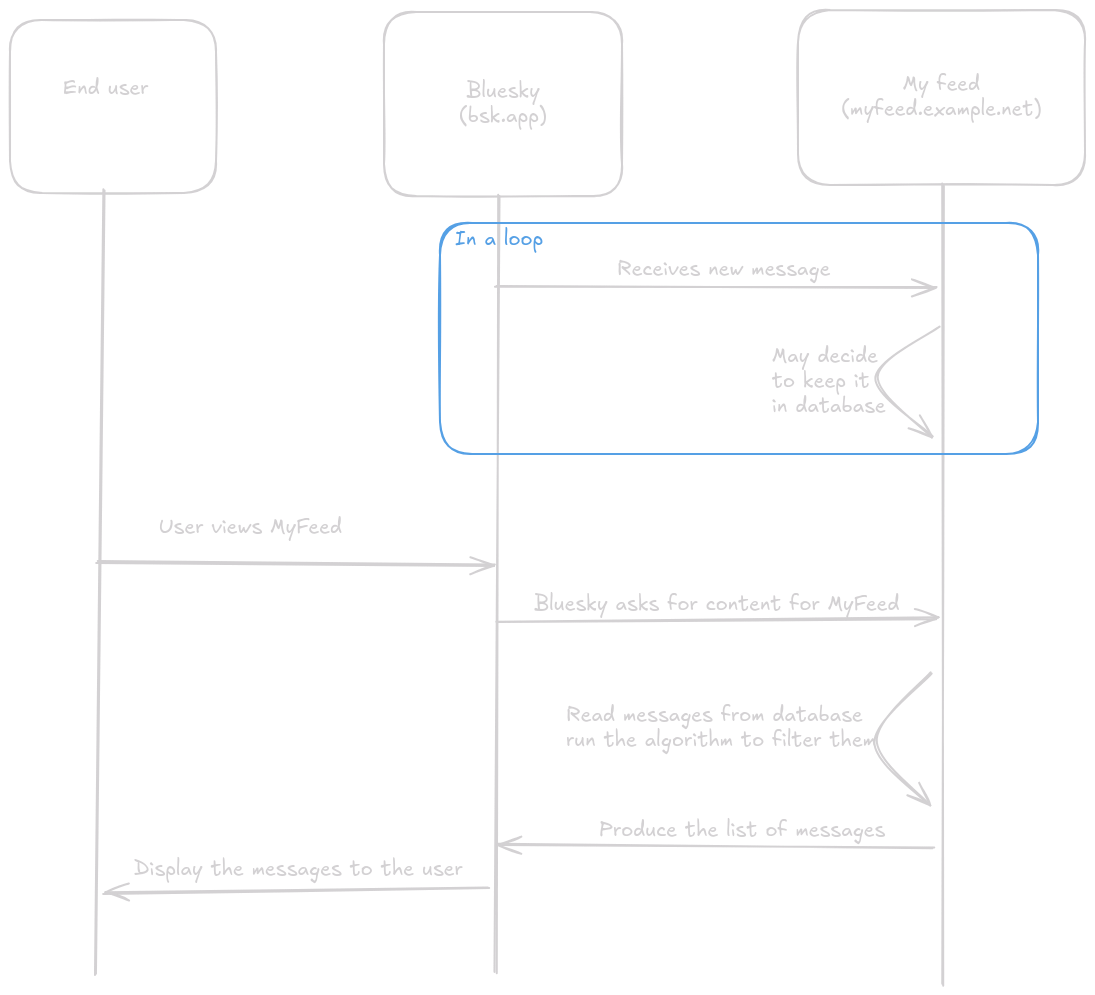
Feed - the source code
Writing your own piece of decentralized system might sound overwhelming but it’s much easier than it sounds. For starters Bluesky provides a handy template repository https://github.com/bluesky-social/feed-generator. Fork that repository, clone it, open it in your favorite IDE and we’re ready to get started!
src/subscription.ts (link)
It contains the message handler. In simple words it’s a function that is executed when a new social network event is received. In the simplest scenario we want to check if the event tells us that some posts have been created/deleted and if so - save them to database.
The platform evolves rapidly so we want to be picky about which messages to save, otherwise we’re out of storage quickly.
The equivalent of this file in Scala feed is https://github.com/polyvariant/scala-feed/blob/main/src/FirehoseSubscription.ts - it’s renamed for convenience as the original repo had two files of the same name.
src/algos/whats-alf.ts (link)
This is the algorithm of your feed. This is where you decide which of the saved messages should be sent to the user, based on the QueryParams. The provided implementation simply reads all messages saved in src/subscription.ts, but you’re free to filter and order them in the way you please.
In this guide we’re not going to change the sources of it, but you probably want to rename the algorithm to something that makes more sense in your use case like we did with src/algos/scala-feed.ts.
It’s important to note that a single server can offer many feeds out of the same database, but that’s more complex use case.
Cooking feed
Now that we covered the baseline, let’s adapt the code. To do this open src/subscription.ts and locate the following code:
import { FirehoseSubscriptionBase, getOpsByType } from './util/subscription'
export class FirehoseSubscription extends FirehoseSubscriptionBase {
async handleEvent(evt: RepoEvent) {
// skipped
const postsToCreate = ops.posts.creates
.filter((create) => {
// only alf-related posts
return create.record.text.toLowerCase().includes('alf') // 👈 we want to change this
})
.map((create) => {
// map alf-related posts to a db row
return {
uri: create.uri,
cid: create.cid,
indexedAt: new Date().toISOString(),
}
})
// skipped
}
}
The reference logic only saves to database the posts that contain the 'alf' substring. Let’s say we want to build a food-related feed, and we are looking for messages that have both #food and #recipe hashtags. Here’s how we would change the code:
import { FirehoseSubscriptionBase, getOpsByType } from './util/subscription'
function isAboutFood(message: string) {
const lowerCaseMessage = message.toLowerCase();
return lowerCaseMessage.contains("#food") && lowerCaseMessage.contains("#recipe");
}
export class FirehoseSubscription extends FirehoseSubscriptionBase {
async handleEvent(evt: RepoEvent) {
// skipped
const postsToCreate = ops.posts.creates
.filter((create) => {
// only food-recipes
return isAboutFood(create.record.text);
})
.map((create) => {
return {
uri: create.uri,
cid: create.cid,
indexedAt: new Date().toISOString(),
}
})
// skipped
}
}
That’s it! No hardcore coding skills required, right?? Now to the last part - the deployment
Deployment
Here are the steps we need to take to integrate the feed with Bluesky network
- Build the source code and deploy it
- Make it available on the internet so that Bluesky can reach it for the feed content
- Register it with Bluesky
Disclaimer
To deploy the feed you need to have a VPS server with Docker installed The cheapest one you can find should probably do just fine for a simple feed
Build
The feed repository as provided by Bluesky developers does not come with any deployment pipeline. There are plenty of ways to deploy an application, and in this guide we’ll focus on containerizing the feed application with Docker.
In the root of your repository create Dockerfile with the following content:
FROM node:22
WORKDIR /app
COPY . .
RUN yarn install && yarn build
RUN rm -rf /build
RUN mkdir /data/
EXPOSE 3000
ENV FEEDGEN_PORT=3000
# Change this to use a different bind address
ENV FEEDGEN_LISTENHOST="0.0.0.0"
# Set to something like db.sqlite to store persistently
ENV FEEDGEN_SQLITE_LOCATION="/data/db.sqlite"
# FEEDGEN_SQLITE_LOCATION=":memory:"
# Don't change unless you're working in a different environment than the primary Bluesky network
ENV FEEDGEN_SUBSCRIPTION_ENDPOINT="wss://bsky.network"
# Set this to the hostname that you intend to run the service at
ENV FEEDGEN_HOSTNAME="vps1234.yourhosting.com" # ⚠️
# Set this to the DID of the account you'll use to publish the feed
# You can find your accounts DID by going to
# https://bsky.social/xrpc/com.atproto.identity.resolveHandle?handle=${YOUR_HANDLE}
ENV FEEDGEN_PUBLISHER_DID="did:plc:hieveesahcai9zozahgh0ain" # ⚠️
# Only use this if you want a service did different from did:web
# FEEDGEN_SERVICE_DID="did:plc:abcde..."
# Delay between reconnect attempts to the firehose subscription endpoint (in milliseconds)
ENV FEEDGEN_SUBSCRIPTION_RECONNECT_DELAY=3000
CMD ["node", "/app/dist/index.js"]
Notice the ⚠️ marks - those are the fields you need to change. The first one should be replaced by the publicly available address of your server. It should be a domain, subdomain of hosting provider is fine. This will be important later in this post.
The other field is your own Bluesky account identifier. You’ll need to have a Bluesky account. Once you register and log in, navigate to https://bsky.social/xrpc/com.atproto.identity.resolveHandle?handle=@yourlogin.bsk.social replacing yourlogin.bsk.social with your handle.
Build the docker image
Now that we have the Dockerfile defined, you can build the image by running docker build -t myfeed . in your repository root.
Bonus: Building the Docker image as part of the GitHub CI/CD
If you plan to publish your feed source code on Github, you can also create .github/workflows/publish-docker-image.yaml with following content:
name: Create and publish a Docker image
on:
release:
types: [published]
push:
branches:
- main
env:
REGISTRY: ghcr.io
IMAGE_NAME: ${{ github.repository }}
jobs:
build-and-push-image:
runs-on: ubuntu-latest
permissions:
contents: read
packages: write
attestations: write
id-token: write
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Log in to the Container registry
uses: docker/login-action@65b78e6e13532edd9afa3aa52ac7964289d1a9c1
with:
registry: ${{ env.REGISTRY }}
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Extract metadata (tags, labels) for Docker
id: meta
uses: docker/metadata-action@9ec57ed1fcdbf14dcef7dfbe97b2010124a938b7
with:
images: ${{ env.REGISTRY }}/${{ env.IMAGE_NAME }}
- name: Build and push Docker image
id: push
uses: docker/build-push-action@f2a1d5e99d037542a71f64918e516c093c6f3fc4
with:
context: .
push: true
tags: ${{ steps.meta.outputs.tags }}
labels: ${{ steps.meta.outputs.labels }}
- name: Generate artifact attestation
uses: actions/attest-build-provenance@v1
with:
subject-name: ${{ env.REGISTRY }}/${{ env.IMAGE_NAME}}
subject-digest: ${{ steps.push.outputs.digest }}
push-to-registry: true
With that, upon each push to main branch Github will build and publish your docker image. This is how it looks like for Scala feed https://github.com/polyvariant/scala-feed/pkgs/container/scala-feed
Deploy
If you went with the bonus part, deploying your image to the server is as simple as running the docker pull command as found in your “packages” section on Github. In other case, we need to deliver the docker image directly from your computer. To do this execute following steps:
docker build -t myfeed . # to build the image
docker save --output=/tmp/myfeed.tar myfeed # to save the image as a file
scp /tmp/myfeed.tar username@vps1234.yourhosting.com:~ # to send the image to your server
Make sure to replace username and vps1234.yourhosting.com with your corresponding server login details. Then you need to login to the server and import the image with following commands:
ssh username@vps1234.yourhosting.com
docker load < ./myfeed.tar
The last thing to do now is to run the feed, which you can do with:
docker run -d --cpus=1 --name myfeed --mount source=myfeedvolume,target=/data -p 8080:3000 myfeed
That’s it! your feed is up and running on the server.
Exposing the service to internet
At this point your feed is likely available at vps1234.yourhosting.com:8080 (can be inaccessible based on firewall rules). This is not enough though, because the traffic is not SSL encrypted. To change that we need a reverse proxy in front of it. For that we’ll use Caddy server. I’ve written about using Caddy server as a reverse proxy before, in this post we’ll just focus on getting things done without much detail.
To expose your feed in a secure way, first install Caddy on your server. To do this follow the install instructions documentation for your server distribution.
Then edit the /etc/caddy/Caddyfile with nano or vim and add following code at the end:
vps1234.yourhosting.com {
reverse_proxy http://127.0.0.1:8080 {
header_up Host {http.reverse_proxy.upstream.hostport}
}
# Enable compression
encode zstd gzip
}
Now reload Caddy with caddy reload. Your feed is now accessible via https://vps1234.yourhosting.com
Register it with Bluesky
So far so good, we have written the code, packaged it, deployed and exposed securely to the internet. Time to tell Bluesky we are ready for some users!
To do this just navigate to your repository root and run yarn publishFeed. There’s a predefined script that will guide you through the process. This is how it looked like for the Scala feed:
✔ Enter your Bluesky handle: @michal.pawlik.dev
✔ Enter your Bluesky password (preferably an App Password):
✔ Optionally, enter a custom PDS service to sign in with: https://bsky.social
✔ Enter a short name or the record. This will be shown in the feed's URL: scala-feed
✔ Enter a display name for your feed: Scala feed
✔ Optionally, enter a brief description of your feed: This feed tracks #Scala along with some other ecosystem related tags
✔ Optionally, enter a local path to an avatar that will be used for the feed: /tmp/scala.png
Summary
This is it, we have went through all the steps of building and publishing our first Bluesky feed. Now that the hard parts are done, make sure to play around with the ATProtocol API and make sure to share your feeds.
If you liked this post, have a feedback or just want to say hi, find me on Bluesky @michal.pawlik.dev!